


像ChatGPT和Google Bard这样的人工智能聊天机器人肯定会大有可为——下一代对话软件工具承诺做一切事情,从接管我们的网络搜索到产生源源不断的创意文学,再到记住世界上所有的知识,这样我们就不用记住了。
ChatGPT、Google Bard和其他类似的机器人都是大型语言模型(llm)的例子,它们的工作原理值得深入研究。这意味着你可以更好地利用他们,更好地了解他们擅长什么(以及他们真的不应该信任什么)。
像许多人工智能系统一样——比如那些用来识别你的声音或生成猫图片的系统——法学硕士是在大量数据上训练的。在披露这些数据的确切来源时,它们背后的公司一直相当谨慎,但我们可以从中找到一些线索。
例如,介绍LaMDA(对话应用语言模型)模型的研究论文提到了维基百科、“公共论坛”和“与编程相关的网站(如问答网站、教程等)的代码文档”。与此同时,Reddit希望开始对其18年的文本对话进行收费,StackOverflow也刚刚宣布计划开始收费。这里的含义是,法学硕士们一直在广泛地使用这两个网站作为资源,直到现在,完全免费,而且是在建立和使用这些资源的人的支持下。很明显,很多网络上的公开信息都被法学硕士们收集和分析过。
llm结合了机器学习和人工输入。
OpenAI由David Nield提供
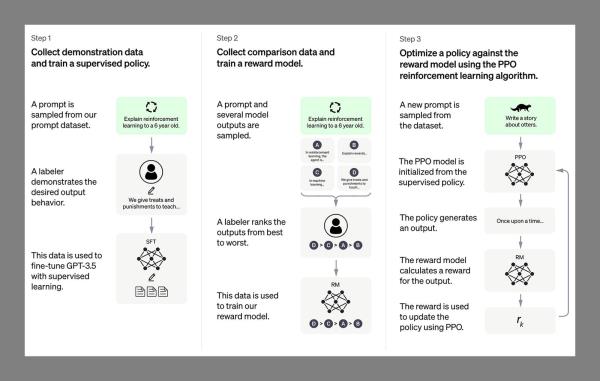
所有这些文本数据,无论来自何处,都会通过神经网络进行处理,这是一种由多个节点和层组成的常用人工智能引擎。这些网络根据一系列因素,包括之前的试验和错误的结果,不断调整它们解释和理解数据的方式。大多数法学硕士使用一种称为转换器的特定神经网络架构,它有一些特别适合语言处理的技巧。(Chat后面的GPT代表生成预训练变压器。)
具体来说,转换器可以读取大量文本,找出单词和短语之间的关系模式,然后预测接下来应该出现哪些单词。你可能听说过有人把法学硕士比作增压的自动纠错引擎,这其实并没有太离谱:ChatGPT和Bard并不真正“知道”任何东西,但他们非常擅长找出哪个单词跟着另一个单词,当它发展到足够高级的阶段时,它开始看起来像真正的思想和创造力。
这些变压器的关键创新之一是自关注机制。在一个段落中很难解释,但本质上它意味着一个句子中的单词不是孤立地考虑的,而是以各种复杂的方式相互联系的。它允许比其他方式更高层次的理解。
代码中内置了一些随机性和可变性,这就是为什么您不会每次都从变形聊天机器人获得相同的响应。这种自动更正的想法也解释了错误是如何潜入的。在基本层面上,ChatGPT和Google Bard不知道什么是准确的,什么是不准确的。他们在寻找看似合理、自然的回答,并与他们接受过的训练数据相匹配。
因此,例如,机器人可能并不总是选择最有可能出现的下一个单词,而是选择第二或第三个最有可能出现的单词。然而,如果做得太过火,句子就会失去意义,这就是法学硕士们总是处于自我分析和自我纠正状态的原因。回答的一部分当然取决于输入,这就是为什么你可以要求这些聊天机器人简化他们的回答或使他们更复杂。
 谷歌通过大卫·尼尔德
谷歌通过大卫·尼尔德
您可能还会注意到生成的文本相当通用或老套——这可能是聊天机器人试图从庞大的现有文本存储库中合成响应时所期望的。在某些方面,这些机器人以与电子表格试图找到一组数字的平均值相同的方式炮制句子,给你留下的输出是完全不起眼的中间路线。例如,让ChatGPT像牛仔一样说话,它将是最不微妙和最明显的牛仔。
人类也参与了这一切(所以我们还不是多余的):训练有素的主管和最终用户都通过指出错误,根据答案的好坏对答案进行排名,并为人工智能提供高质量的结果来帮助培训法学硕士。从技术上讲,它被称为“基于人类反馈的强化学习”(RLHF)。llm然后进一步完善他们的内部神经网络,以便下次得到更好的结果。(在这个层面上,这项技术还处于相对早期的阶段,但我们已经看到了许多来自开发者的升级和改进通知。)
随着这些法学硕士变得越来越大、越来越复杂,它们的能力也会提高。我们知道ChatGPT-4有大约1万亿个参数(尽管OpenAI不会确认),而ChatGPT 3.5有1750亿个参数——参数是通过数字和算法连接单词的数学关系。在理解单词之间的关系以及知道如何将它们连接在一起以产生反应方面,这是一个巨大的飞跃。
从法学硕士的工作方式来看,很明显,他们非常擅长模仿他们受过训练的文本,并写出听起来自然而有见地的文本,尽管有点平淡无奇。通过他们的“高级自动更正”方法,他们将在大多数情况下获得正确的事实。(很明显,“美国第一任总统是……”)但从这里开始,他们就开始跌倒了:排在后面的单词并不总是那个。

